Watch and Act: Learning Robotic Manipulation from Visual Demonstration
1School of Control Science and Engineering, Shandong University 2Department of Automation, Shanghai Jiao Tong University
Abstract
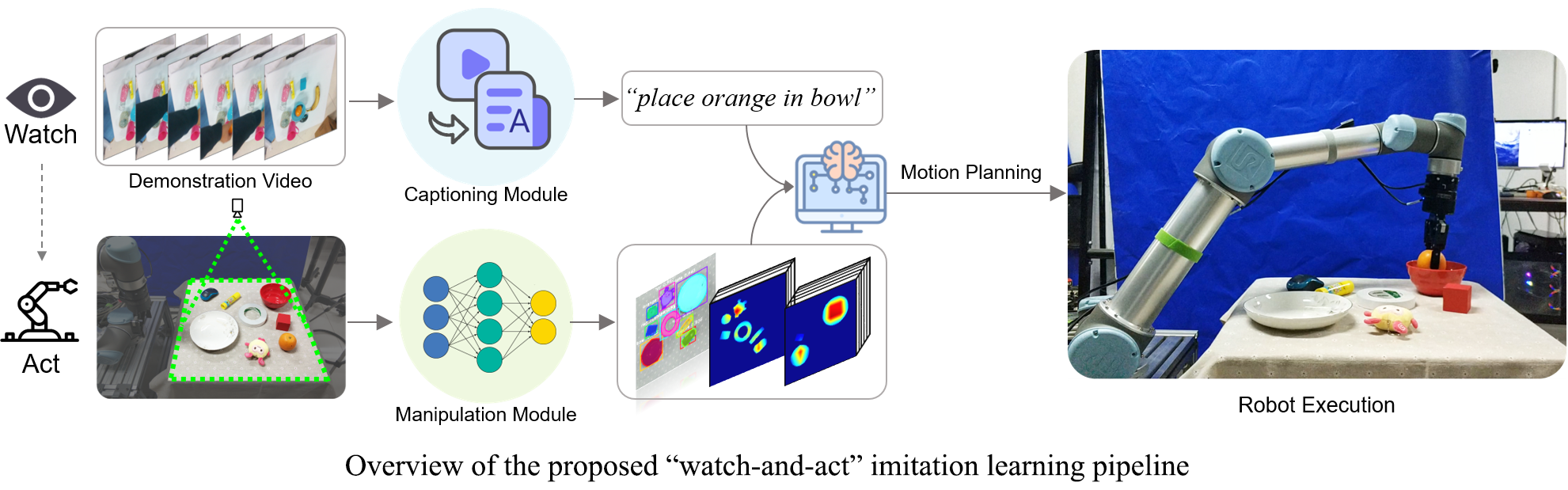
Learning from demonstration holds the promise of enabling robots to learn diverse actions from expert experience. In contrast to learning from observation-action pairs, humans learn to imitate in a more flexible and efficient manner: learning behaviors by simply "watching". In this paper, we propose a "watch-and-act" imitation learning pipeline that endows a robot with the ability of learning diverse manipulations from visual demonstration. Specifically, we address this problem by intuitively casting it as two subtasks: understanding the demonstration video and learning the demonstrated manipulations. First, a captioning module based on visual change is presented to understand the demonstration by translating the demonstration video to a command sentence. Then, to execute the captioning command, a manipulation module that learns the demonstrated manipulations is built upon an instance segmentation model and a manipulation affordance prediction model. We validate the superiority of the two modules over existing methods separately via extensive experiments and demonstrate the whole robotic imitation system developed based on the two modules in diverse scenarios using a real robotic arm.